Best GPU hardware for DeepSeek models in 2025. Get expert insights on specs, performance, and recommendations for optimal AI and deep learning.

DeepSeek models continue to push the boundaries of large language model (LLM) performance, offering unparalleled capabilities across various domains. However, their computational demands remain substantial, necessitating careful hardware selection. This guide provides updated system requirements, including VRAM estimates, GPU recommendations, and optimization strategies for all DeepSeek model variants in 2025, along with insights into ProX PC’s GPU servers and workstations tailored for these needs. Explore custom workstations at proxpc.com
The hardware demands of DeepSeek models depend on several critical factors:
ProX PC offers cutting-edge GPU servers and workstations designed to meet the demanding requirements of AI workloads like DeepSeek models. With a strong emphasis on reliability, scalability, and efficiency, ProX PC provides:
Centralized Management: Integrated with ProX PC’s centralized portal for ticketing, monitoring, and maintenance, providing a hassle-free experience.
Check out our ProX AI SuperServer, designed for scalable AI deployments.
Customizable Configurations: Tailored to specific DeepSeek model variants and use cases.
Explore our ProX AI Workstation, perfect for researchers and developers.
- Model Inferencing Workstation
By offering a one-stop solution, ProX PC ensures smooth deployment and management for AI enthusiasts, researchers, and enterprises alike.
| Model Variant | FP16 Precision (VRAM) | 4-bit Quantization (VRAM) |
|---|---|---|
| 7B | ~14 GB | ~4 GB |
| 16B | ~30 GB | ~8 GB |
| 100B | ~220 GB | ~60 GB |
| 671B | ~1.2 TB | ~400 GB |
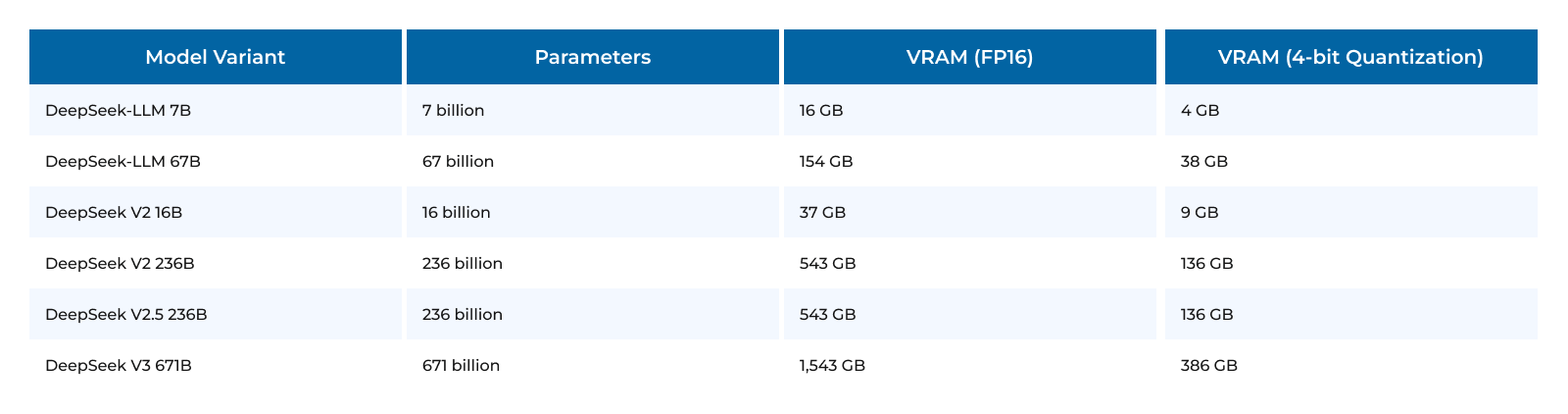
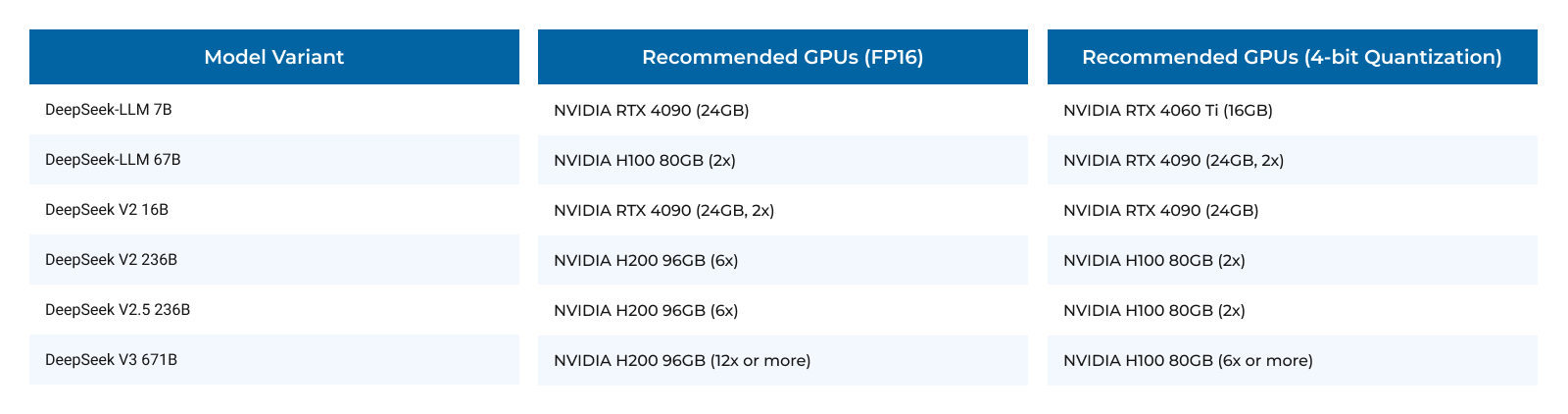
Based on VRAM requirements, the following GPUs are recommended:
| Model Variant | Consumer GPUs | Data Center GPUs |
| 7B | NVIDIA RTX 4090, RTX 6000 | NVIDIA A40, A100 |
| 16B | NVIDIA RTX 6000, RTX 8000 | NVIDIA A100, H100 |
| 100B | N/A | NVIDIA H100, H200 (multi-GPU setups) |
| 671B | N/A | NVIDIA H200 (multi-GPU setups) |
| GPU Model | VRAM | FP16 TFLOPS | Efficiency (DeepSeek) |
| RTX 4090 | 24 GB | 82.6 | Best for 7B models |
| RTX 6000 (Ada) | 48 GB | 91.1 | Ideal for 7B-16B |
| A100 | 40/80 GB | 78 | Enterprise-grade for 16B-100B |
| H100 | 80 GB | 183 | Optimal for 100B+ |
| H200 (2025) | 100 GB | 250 | Best for 671B |
To efficiently deploy DeepSeek models, consider these practical optimization techniques:
DeepSeek models continue to advance AI capabilities, but their hardware requirements demand careful planning. ProX PC’s range of GPU servers and workstations offers the perfect balance of power, scalability, and support to meet these demands.
For smaller models (e.g., 7B and 16B), consumer GPUs like the NVIDIA RTX 4090 provide a cost-effective solution. Larger models necessitate data center-grade GPUs such as the H100 or H200, often in multi-GPU configurations. By choosing the right hardware and applying optimization strategies, you can deploy DeepSeek models efficiently at any scale in 2025.
Explore more about our products, such as the ProX AI Edge Server and ProX Scalable Rack Solutions, to elevate your AI deployment.
Resources you may find helpful.

Know the essential system requirements for Adobe Photoshop in 2025. This guide covers the recommended hardware and software to ensure smooth and efficient performance, whether you're a beginner or a professional editor.

The essential system requirements for Adobe Lightroom in 2025. Ensure your hardware and software are optimized for flawless performance.

Know the essential hardware requirements for Stable Diffusion. Explore minimum specs and recommended setups for smooth AI image and video generation.

The minimum and recommended system requirements for Windows and macOS to run Premiere Pro efficiently. Optimize performance with system hardware requirement insights.
