Building Enterprise-Grade RAG Systems with Pro Maestro: The Future of AI-Powered Document Intelligence

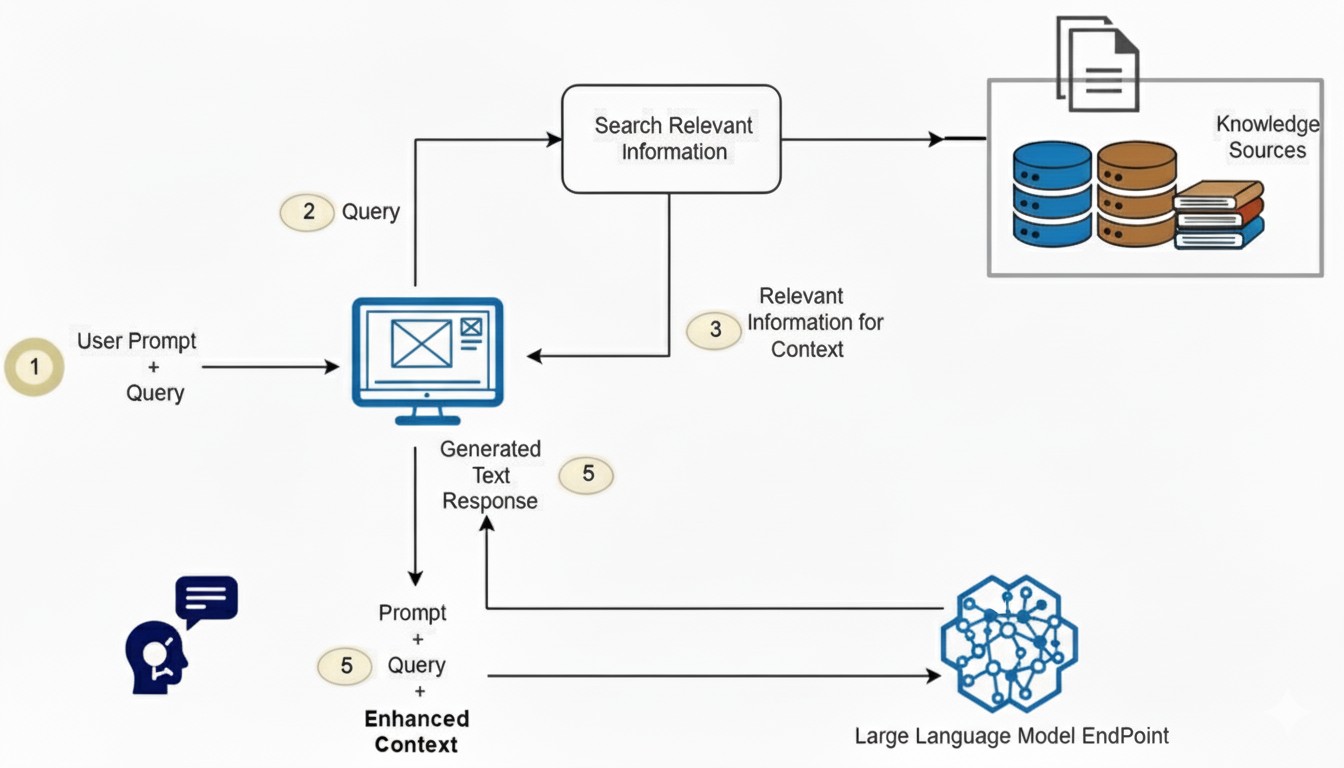
Without RAG, an LLM generates a response directly from its training data. With RAG, an additional retrieval component comes into play.
The user query is taken in.
The system searches for relevant information in external knowledge bases such as APIs, databases, or document repositories.
For example, if an employee asks a chatbot, “How much annual leave do I have?”, the system doesn’t just rely on generic HR knowledge. Instead, it retrieves:
The company’s annual leave policy documents.
The employee’s individual leave balance records.
This ensures the response is accurate and personalized.
The external data used in RAG—known as external knowledge—can come in different forms: PDFs, structured databases, APIs, or long-form text.
To make this data searchable, it is first transformed into embeddings (numerical vector representations of text). These embeddings are stored in a vector database, essentially creating a searchable knowledge library.
When a new query comes in, it’s also converted into an embedding. The system then performs a relevance search, matching the query embedding with the closest data embeddings in the vector database.
Once the relevant data is found, it’s added as context to the user’s query. This is called prompt augmentation.
The LLM now generates a response based not only on its training but also on the most relevant, up-to-date information. This combination of retrieval + generation leads to answers that are more accurate, context-aware, and reliable.
One challenge with RAG is keeping external data up to date. Over time, policies, documents, or databases may change, leading to stale results.
To solve this, organizations can:
Continuously update documents and embeddings in real time.
Run scheduled batch updates to refresh the knowledge base.
By doing so, the RAG system remains current and trustworthy, even as the underlying data evolves.
The Pro Maestro platform showcases enterprise-grade specifications designed for demanding AI workloads. With support for up to 192 cores of AMD/Intel processing power, up to 4TB DDR5 ECC RAM, and up to 4x 600W GPUs with 564GB combined VRAM, this system provides the computational foundation necessary for running sophisticated RAG implementations locally. The platform's architecture includes up to 125TB flash storage and 200TB HDD storage, ensuring ample capacity for large-scale document repositories and vector databases.
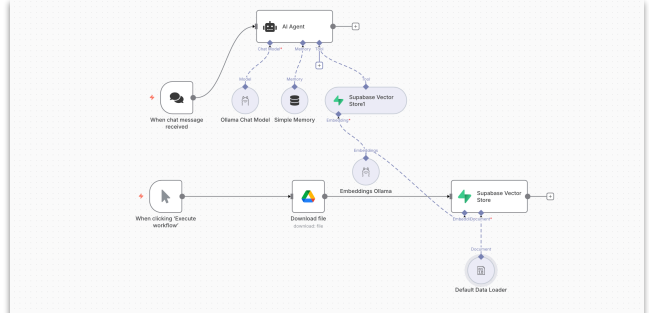
The Pro Maestro platform enables the deployment of advanced RAG systems using N8N workflow automation integrated with the powerful GPT-OSS 120B model running on Ollama. This implementation represents a significant advancement in local AI deployment, eliminating dependencies on cloud services while maintaining enterprise-grade performance.
The RAG implementation leverages several key technologies working in harmony. N8N serves as the orchestration layer, providing visual workflow automation that connects document processing, embedding generation, and query handling through intuitive nodes. The GPT-OSS 120B model, deployed locally via Ollama, delivers exceptional performance with up to 156 tokens per second processing speed while maintaining complete data privacy.
The system utilizes a locally hosted Supabase database instance configured with vector storage capabilities, enabling efficient similarity searches across embedded document content. This architecture ensures that sensitive enterprise data never leaves the local environment while providing rapid response times for user queries.
The N8N workflow architecture consists of strategically designed nodes that handle the complete RAG pipeline. The Chat Node serves as the user interface, capturing queries and presenting AI-generated responses in a conversational format. The AI Agent Node, powered by GPT-OSS 120B, processes user questions and formulates responses based on retrieved context from the vector database.
Document processing begins when PDF files are uploaded to the system. The Ollama embedding model, running locally on the Pro Maestro platform, processes these documents to generate dense vector representations. These embeddings are stored in the Supabase vector database, creating a searchable knowledge base that enables semantic similarity matching.
The RAG system transforms how organizations access and utilize their institutional knowledge. Human Resources departments can instantly query employee handbooks, policy documents, and compliance materials, receiving accurate, contextual responses without manual document searches. Account managers gain immediate access to historical client interactions, quarterly business reviews, and contract details through natural language queries.
Engineering teams benefit from AI-powered access to API documentation, technical specifications, and development guides. The system can generate code examples, explain implementation procedures, and provide troubleshooting guidance based on comprehensive technical documentation repositories.
Legal departments utilize the RAG system to quickly reference statutes, case law, and regulatory requirements. The system's ability to cite specific sources and provide accurate information reduces the risk of compliance errors while accelerating legal research processes.
The Pro Maestro platform's multi-GPU architecture enables parallel processing of large language models, significantly reducing response times compared to cloud-based alternatives. With 400GB/s network bandwidth, the system handles high-volume query loads without performance degradation.
Local deployment ensures that proprietary documents and sensitive information never leave the enterprise environment. This approach eliminates data breach risks associated with cloud processing while maintaining compliance with strict data protection regulations.
Organizations avoid recurring cloud API fees, which can reach $2.50 per million input tokens and $10.00 per million output tokens for enterprise-grade models. The Pro Maestro platform provides unlimited local processing capacity, delivering substantial cost savings for high-volume applications.
Successful RAG implementations require meticulous attention to data quality. Organizations should establish regular data refresh schedules and integrate diverse, credible sources to reduce bias in AI responses. The embedding process benefits from domain-specific fine-tuning to improve retrieval accuracy.
The Pro Maestro platform's modular design supports scaling from proof-of-concept implementations to enterprise-wide deployments. Organizations should plan for increased data volumes and user loads by leveraging the platform's expandable storage and processing capabilities.
Production RAG systems require ongoing monitoring of accuracy, relevance, and response quality. The N8N workflow environment enables real-time performance tracking and automated system adjustments based on user feedback and usage patterns.
The Pro Maestro platform positions organizations for emerging AI trends beyond 2025. Multimodal integration capabilities will enable processing of text, images, and structured data within unified RAG workflows. Adaptive intelligence features will allow systems to self-improve based on user interactions and feedback patterns.
Federated learning capabilities will enable secure, decentralized RAG deployments across multiple organizational units while preserving data privacy. The platform's robust hardware foundation supports these advanced implementations without requiring infrastructure upgrades.
The Pro Maestro platform represents a paradigm shift in enterprise AI deployment, combining powerful local processing capabilities with sophisticated RAG implementations. By leveraging N8N workflow automation, Ollama local model deployment, and advanced vector database technologies, organizations achieve unprecedented control over their AI infrastructure while delivering superior performance and security.
This comprehensive approach to RAG implementation demonstrates how modern enterprises can harness the full potential of their data assets while maintaining complete operational autonomy. The Pro Maestro platform's scalable architecture ensures that organizations can grow their AI capabilities alongside their business needs, establishing a foundation for sustained competitive advantage in the AI-driven economy.
If you’re looking to scale your workflow, speed up production, or handle heavier projects without compromise, you can check out our Pro Maestro Series
A range of purpose-built systems designed as real solutions to real professional challenges. We’re a solution-oriented brand, focused on building machines that make your work faster, smoother, and more reliable.
Pro Maestro GQ (4 GPU Server)
A compact powerhouse for 3D rendering, animation, and AI prototyping. Ideal for small studios and creators who need high performance in limited space.
Pro Maestro GE (8 GPU Server)
An exclusive in India, supporting the latest GeForce RTX 5090 series GPUs. Built for AI training, deep learning, simulation, and high-end VFX — the kind of system serious professionals rely on for heavy compute workloads.
Pro Maestro GD (10 GPU Server)
Our most advanced dense-architecture system, optimized for LLM training, large-scale simulation, and enterprise-grade rendering. Perfect for research institutions and data centers pushing performance limits.
From AI and VFX to simulation and generative workloads. The Pro Maestro Series turns complex computing into effortless performance.
Resources you may find helpful.

ProX PC Maestro Servers offer the powerful GPUs, ample memory, and scalable features needed to supercharge your deep learning projects.

ProX PC servers offer top performance, scalability, and reliability for big data and deep learning, making them ideal for various industries. Invest smartly with ProX PC.

Discover the future of AI with ProX PC's 8 GPU servers featuring NVIDIA RTX 4090 GPUs. Unmatched performance, reliability, and scalability for all your machine learning needs.

In the fast-evolving world of computational technology, choosing the right hardware can significantly impact the performance of scientific and engineering workloads. In this post, we will compare the numerical computing performance of the new AMD Zen4 Threadripper PRO (specifically the 7995WX and 7985WX) against the Intel Xeon W-9 3495X and the older Threadripper 7980X. We will also briefly mention the previous generation Threadripper PRO 5995WX with Zen3 optimizations.



