Expert Analysis & Hardware Insights for Professional Editors and AI Researchers of Nvidia’s new AI Magic easier for Video.

For video professionals, the phrase "fix it in post" usually implies hours of tedious manual labor. While image editing has matured, removing moving objects from video remains a significant technical bottleneck. Traditional methods often fail to keep the video smooth, leaving behind flickering artifacts or "ghostly" footprints like shadows and reflections that break the illusion of reality.
At ProX PC , we closely monitor these advancements to understand the hardware infrastructure required to support them. The recent unveiling of OmnimatteZero by NVIDIA Research represents a massive change in how we work. It offers a training-free, real-time solution that respects the physics of a scene, moving beyond simple pixel-filling to true scene decomposition.
Presented at SIGGRAPH Asia 2025, OmnimatteZero is a collaborative breakthrough involving NVIDIA Research, OriginAI, and academic partners.
Unlike previous methods that required training an AI model on a specific video for hours ("One-Shot Tuning"), OmnimatteZero is a Zero-Shot solution. It uses pre-trained video models the same technology used for generative video to perform subtractive editing instantly.
To understand why this model succeeds where others fail, we must look at the underlying architecture described in the research.

Legacy inpainting models often treat video as a sequence of independent images, resulting in "flicker" where the background texture shifts from frame to frame. OmnimatteZero solves this using Mean Temporal Attention.
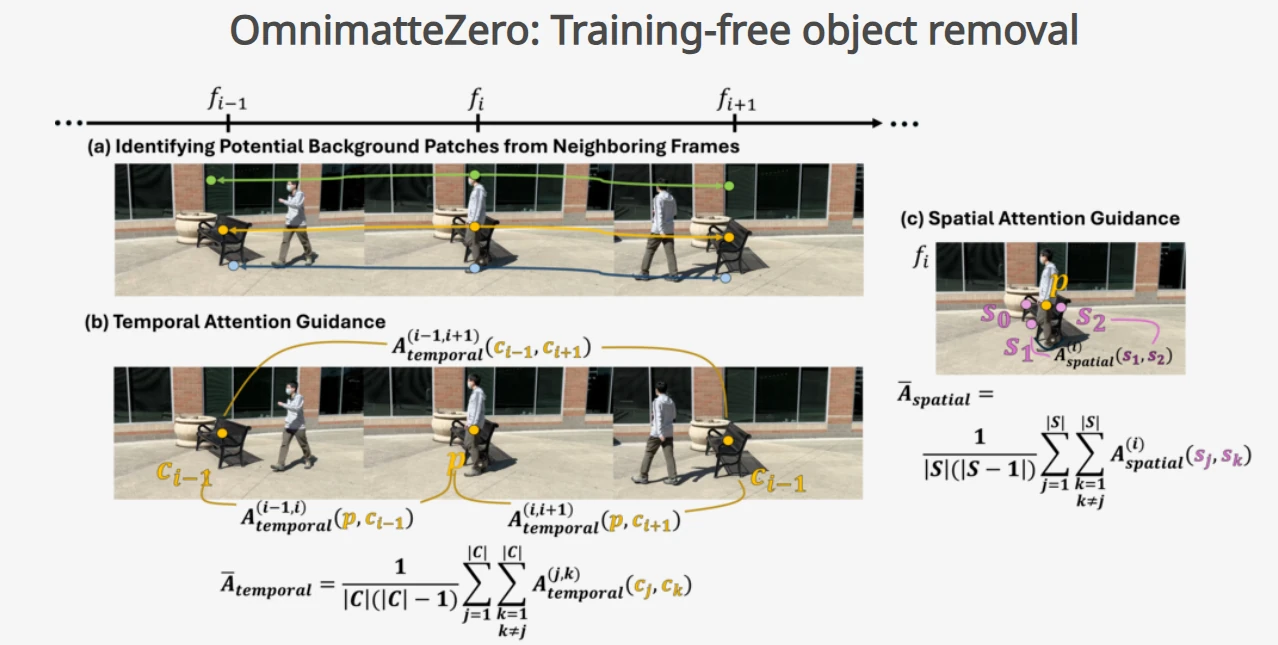
A major flaw in earlier AI erasers is their inability to distinguish between an object and its environmental impact. Removing a boat but leaving its reflection renders a shot unusable. OmnimatteZero utilizes Cross-Attention Maps to enforce the Gestalt principle of "Common Fate."
The research paper highlights a stunning benchmark: 0.04 seconds per frame processing speed. This is effectively real-time. However, achieving this performance locally requires specific hardware considerations.
When working with video diffusion models like OmnimatteZero, VRAM (Video Random Access Memory) is the most critical factor. While computational speed determines how fast a frame renders, VRAM determines if it can render at all.
Here is the breakdown of why memory capacity is the true gatekeeper for this technology:
The ProX PC Solutions
As this technology moves from research paper to open-source code (targeted for early 2026), the bottleneck will shift from software to hardware. Running diffusion-based video editing tools locally requires a system designed for sustained thermal loads and high-throughput memory operations.
At ProX PC, we engineer systems specifically for these generative workflows. By pairing high-frequency processors with massive VRAM pools, we ensure that when the software update arrives, your hardware is ready to render reality in real-time.
The Pro Maven is our flagship desktop workstation designed for individual editors and AI researchers.
The Pro Maestro is our high-density server solution, built for studios that need to scale their AI capabilities.
Email:sales@proxpc.com
Phone:011-40727769
Visit:https://www.proxpc.com/
Resources you may find helpful.

AI is revolutionizing the hardware industry by boosting design, manufacturing, maintenance, supply chains, personalization, autonomy, security, and energy efficiency.

Discover model-inferencing workstations: advanced AI systems revolutionizing industries from retail to smart cities and mastering complex tasks with cutting-edge technology.

Explore how hybrid systems revolutionize transportation, energy, manufacturing, and daily life by integrating diverse technologies for innovative solutions.

Delve into Edge AI's impact on latency, privacy, and autonomy. Uncover its applications in healthcare, manufacturing, retail, and security.
