Unlock the full potential of your simulations with multi-GPU servers. Scale computational power, accelerate workloads, and achieve faster, more accurate results for complex tasks.

The simulation landscape has reached a tipping point. Whether you're running computational fluid dynamics (CFD), finite element analysis (FEA), or complex engineering simulations, the demand for computational horsepower has never been higher. Single-GPU setups that once seemed powerful now struggle with today's massive datasets and intricate models. That's where multi-GPU server configurations like the Pro Maestro series come into play, offering unprecedented scaling potential that can transform weeks of computation into hours of productive work.
Modern simulation workloads are pushing the boundaries of what single GPUs can handle. Take a typical CFD simulation of airflow over a full car geometry – something that would traditionally take several days on standard CPUs can be reduced to hours with proper GPU acceleration. However, even powerful single GPUs encounter limitations when dealing with:
Massive memory requirements exceeding 32GB
Complex mesh geometries requiring parallel processing across thousands of elements
Real-time simulations needing instant feedback
Multi-physics problems combining structural, thermal, and fluid analysis
Multi-GPU scaling isn't just theoretical – the numbers speak for themselves. Research shows that multi-GPU setups can achieve nearly 8x performance increases compared to traditional CPU workflows. More importantly, proper multi-GPU scaling can deliver 2-4x performance improvements over single-GPU configurations, depending on the simulation type and workload characteristics.
The key to this performance lies in tensor parallelism – distributing model weights and computations across multiple accelerators. While perfect linear scaling (2 GPUs = 2x performance) remains elusive due to communication overhead, well-optimized multi-GPU systems consistently deliver 70-85% scaling efficiency.
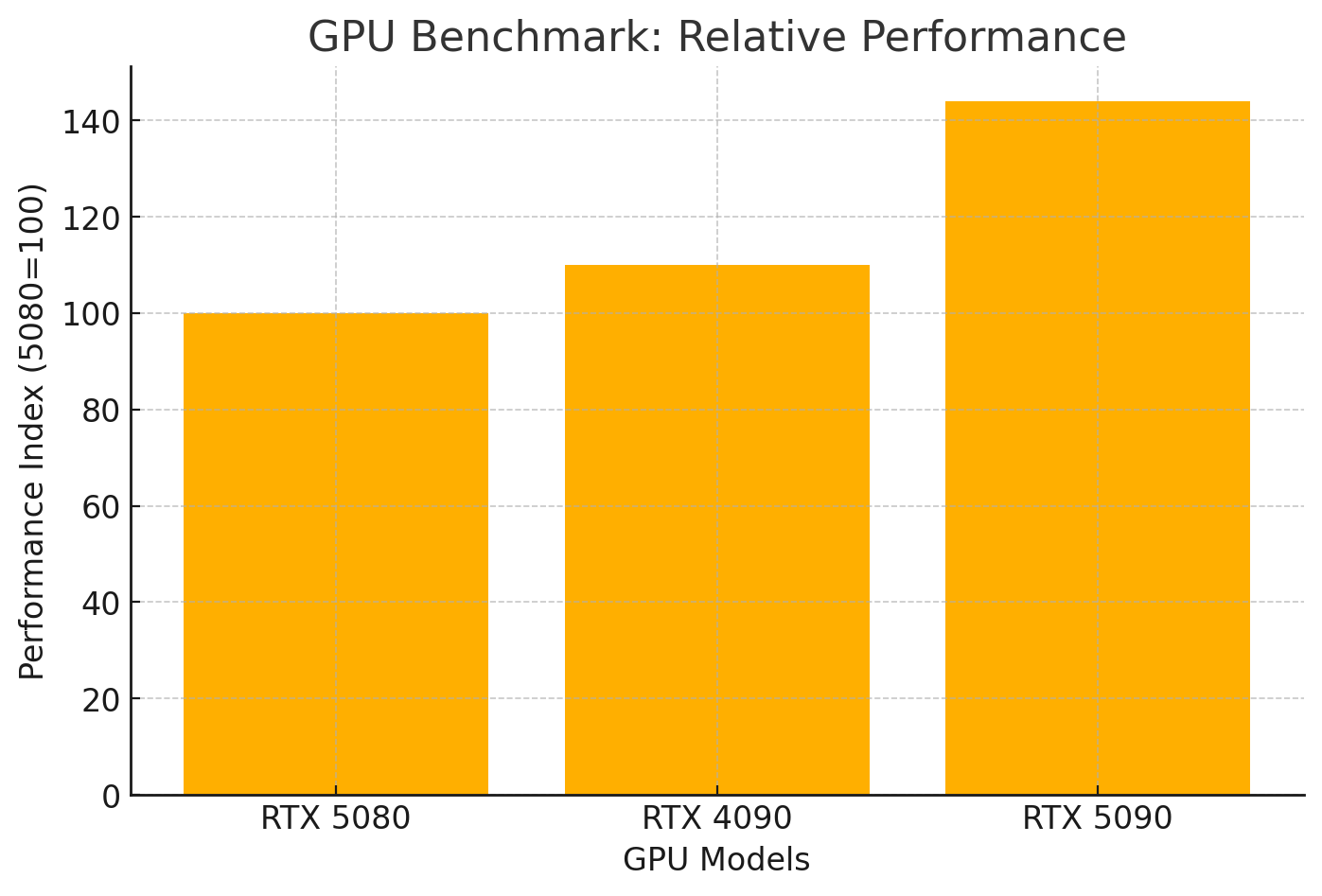
The RTX 5090 has surprised everyone by becoming a legitimate simulation powerhouse. Built on NVIDIA's Blackwell architecture with 32GB of GDDR7 memory and 21,760 CUDA cores, it delivers impressive real-world performance:
32GB GDDR7 memory with 512-bit bus
21,760 CUDA cores
680 5th generation Tensor Cores (+33% over previous generation)
27% increase in FP/BF16 performance (165.2 TFLOPS baseline)
44% overall performance lead over RTX 5080 across synthetic benchmarks
47% faster rendering in Blender compared to RTX 5080
40% improvement over RTX 4090 in AI workloads
Exceptional scaling in memory-heavy workloads where performance deltas reach 48-52%
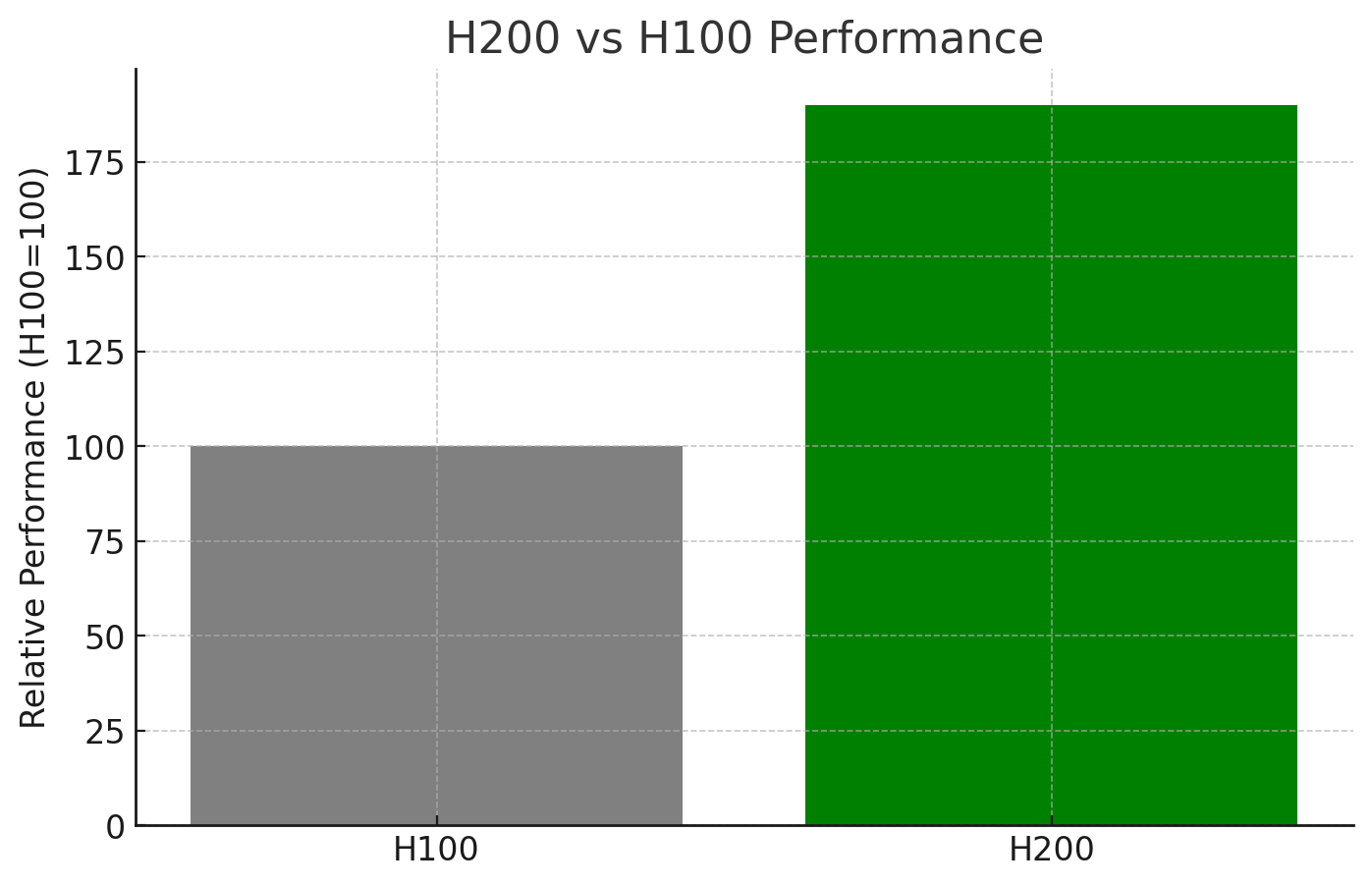
For memory-intensive simulations, the H200 stands in a class of its own. With 141GB of HBM3e memory and 4.8TB/s memory bandwidth, it's designed for workloads that would choke other GPUs:
141GB HBM3e memory (76% more than H100)
4.8TB/s memory bandwidth (43% faster than H100)
1,979 TFLOPS FP16 performance
3,958 TFLOPS FP8 performance
1.9x performance increase over H100 in Llama2-13B inference
47% boost in graph neural network training compared to H100
11,819 tokens per second on Llama2-13B model
The H200's massive memory capacity makes it ideal for large-scale CFD simulations and complex FEA models that require storing extensive mesh data and solution vectors simultaneously.
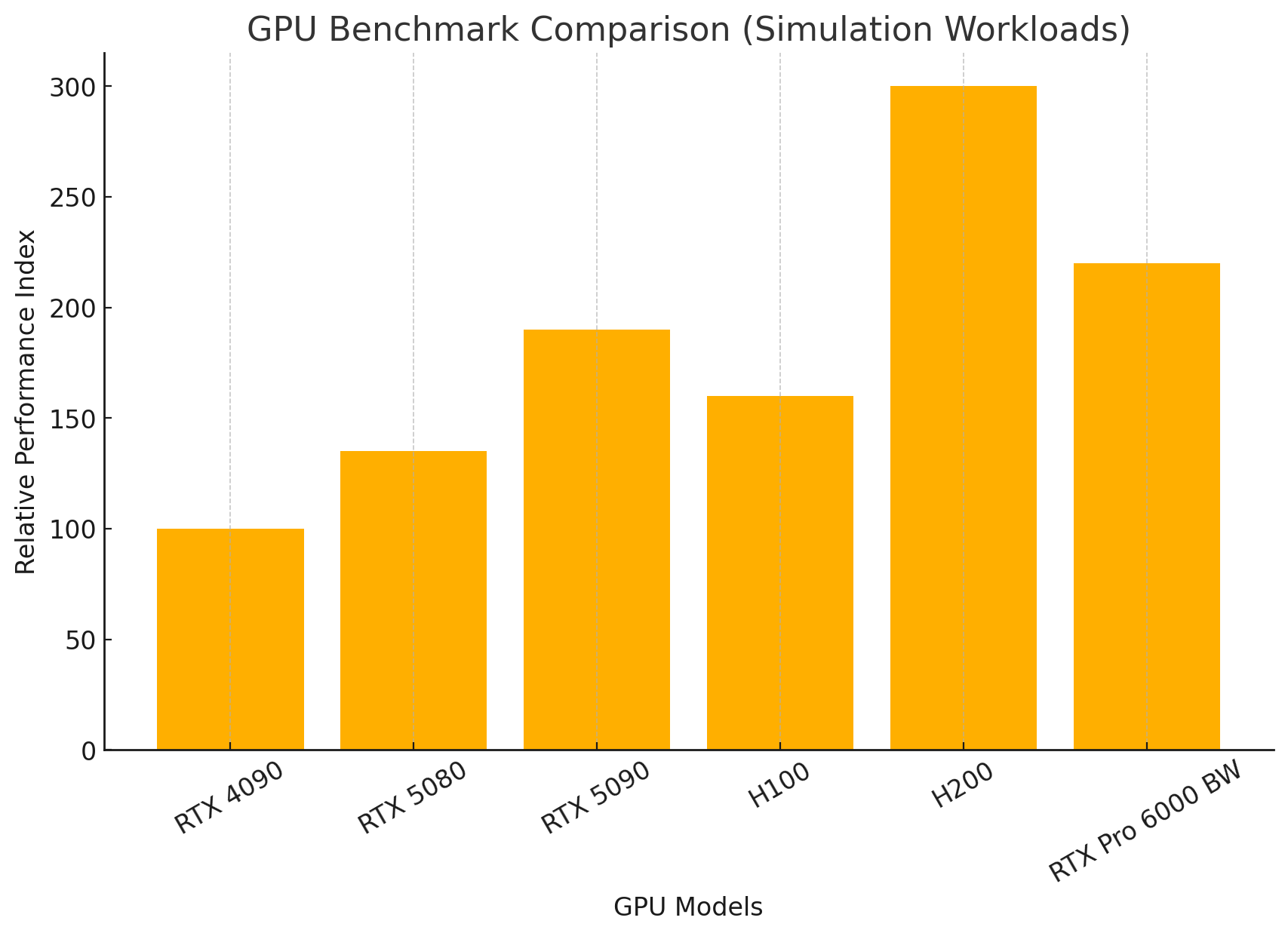
The RTX Pro 6000 Blackwell represents the pinnacle of professional GPU engineering. With 96GB of GDDR7 memory and 24,064 CUDA cores, it bridges the gap between gaming GPUs and data center accelerators:
96GB GDDR7 memory with ECC for error correction
24,064 CUDA cores (+460% over original RTX 6000)
126 TFLOPS floating-point performance
752 Tensor Cores and 188 RT Cores
130% performance improvement over original Quadro RTX 6000
This GPU excels in professional simulation environments where data integrity and reliability are paramount, making it perfect for aerospace, automotive, and medical device simulations.
The Pro Maestro GQ represents the perfect entry point into high-performance multi-GPU simulation computing. This 4-GPU configuration provides excellent price-to-performance ratio for medium-scale simulations:
3.2-3.6x performance scaling over single GPU setups
Optimal for CFD simulations with 10-50 million cells
Perfect for parametric studies requiring multiple simultaneous runs
Ideal for engineering teams transitioning from single-GPU workstations
The Pro Maestro GE offers exceptional flexibility with dual configuration options to match your specific simulation needs:
256GB total GDDR7 memory (8 x 32GB RTX 5090)
174,080 total CUDA cores
Estimated 6.5-7.2x performance scaling for memory-bound simulations
Perfect for high-throughput parametric studies and real-time design optimization
Up to 1.128TB total memory (8 x 141GB H200)
38.4TB/s aggregate memory bandwidth
Exceptional performance for memory-intensive CFD and multi-physics simulations
Ideal for automotive aerodynamics, aerospace thermal analysis, and large-scale FEA
Both configurations excel in demanding simulation workloads, with the RTX 5090 setup offering outstanding price-to-performance for most engineering applications, while the H200 configuration provides unmatched memory capacity for the most complex simulations.
The Pro Maestro GD 10-GPU configuration pushes the boundaries of workstation-class computing,especially when equipped with H200 accelerators:
1.41TB total memory (10 x H200 141GB configuration)
48TB/s aggregate memory bandwidth
Suitable for the most demanding simulation workloads and real-time analysis
Perfect for oil & gas reservoir modeling and weather simulation
ANSYS has been a pioneer in GPU acceleration since 2010, and their implementation shows impressive results on Pro Maestro systems:
Direct solver acceleration for sparse matrix operations
Iterative solver support for large-scale problems
Compatible with both NVIDIA RTX series and data center GPUs
Simple activation through Solution Process Settings
Performance improvements vary by problem size, but users typically see 2-4x speedup on GPU-optimized solvers compared to CPU-only configurations.
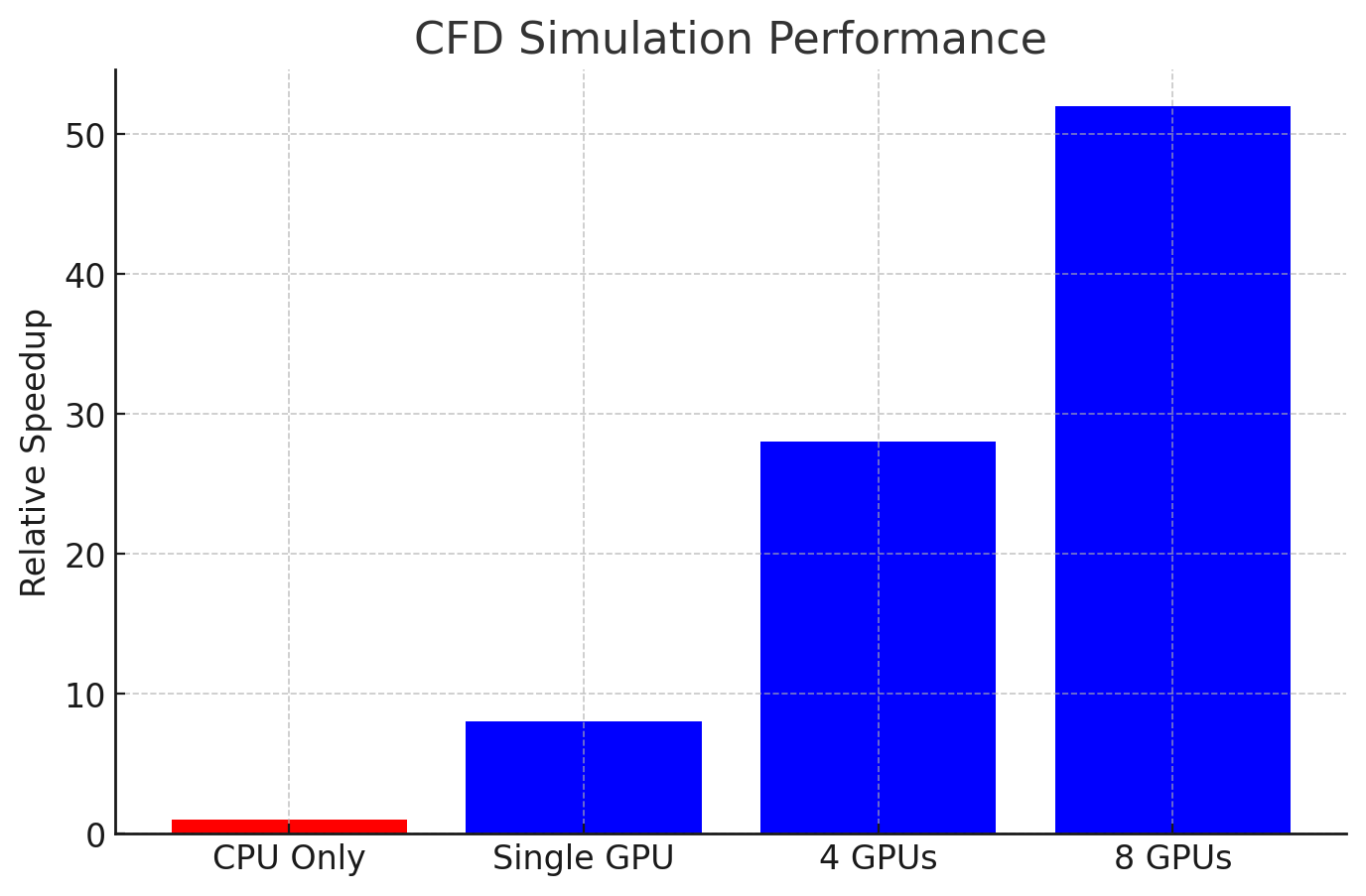
Computational Fluid Dynamics applications benefit tremendously from Pro Maestro multi-GPU setups:
8x performance increase moving from CPU to GPU workflows
Linear scaling up to 4-6 GPUs for well-partitioned problems
Memory bandwidth becomes the limiting factor in large simulations
Pro Maestro GE and GD configurations excel in memory-intensive CFD
Raw performance is only part of the story. What makes the Pro Maestro series stand apart isn’t just the multi-GPU horsepower — it’s the ecosystem of support behind it. From manufacturing to deployment to ongoing maintenance, we handle the entire lifecycle so your engineering team can stay focused on simulation, not troubleshooting.
With a nationwide network of 7,500+ skilled technicians, you get coverage wherever you are. That means fast response times, reliable on-site assistance, and peace of mind knowing your systems are always running at peak performance.
Our goal is simple: deliver multi-GPU infrastructure that feels invisible in day-to-day use. No downtime headaches, no endless support calls — just stable, scalable simulation servers backed by a service network built for professionals.
The simulation landscape is evolving fast, and single-GPU systems can’t keep up with the size and complexity of modern workloads. The Pro Maestro GQ, GE, and GD give you the power to scale CFD, FEA, and multi-physics simulations to new heights — and with our nationwide service coverage, you’ll never be left alone managing the complexity.
In short, you don’t just get a server. You get a long-term partner in performance, ensuring your simulations run faster, scale further, and stay reliable from day one.
Resources you may find helpful.

ProX PC Maestro Servers offer the powerful GPUs, ample memory, and scalable features needed to supercharge your deep learning projects.

ProX PC servers offer top performance, scalability, and reliability for big data and deep learning, making them ideal for various industries. Invest smartly with ProX PC.

Discover the future of AI with ProX PC's 8 GPU servers featuring NVIDIA RTX 4090 GPUs. Unmatched performance, reliability, and scalability for all your machine learning needs.

In the fast-evolving world of computational technology, choosing the right hardware can significantly impact the performance of scientific and engineering workloads. In this post, we will compare the numerical computing performance of the new AMD Zen4 Threadripper PRO (specifically the 7995WX and 7985WX) against the Intel Xeon W-9 3495X and the older Threadripper 7980X. We will also briefly mention the previous generation Threadripper PRO 5995WX with Zen3 optimizations.



